

{kind=link}
This examine makes use of superior deep studying strategies to categorise breast ultrasound pictures into benign, malignant, and regular classes with the assistance of the EfficientNet-B7 mannequin. To enhance accuracy, particularly for much less widespread instances, the photographs are enhanced by way of strategies like random flipping, rotation, and colour changes. Your complete mannequin is fine-tuned to go well with the specifics of ultrasound pictures, and coaching is rigorously monitored to cease earlier than overfitting happens. In contrast to conventional strategies that depend on handbook or fundamental choice of necessary picture frames, this method makes use of deep studying to mechanically concentrate on probably the most crucial areas for analysis. Moreover, Explainable AI strategies, comparable to Grad-CAM, are used to visually verify the mannequin’s decision-making course of, making the outcomes extra comprehensible and reliable. Determine 2 reveals the overview of the proposed methodology leveraging EfficientNet-B7 for breast ultrasound picture classification.

Workflow of the proposed mannequin
Dataset description
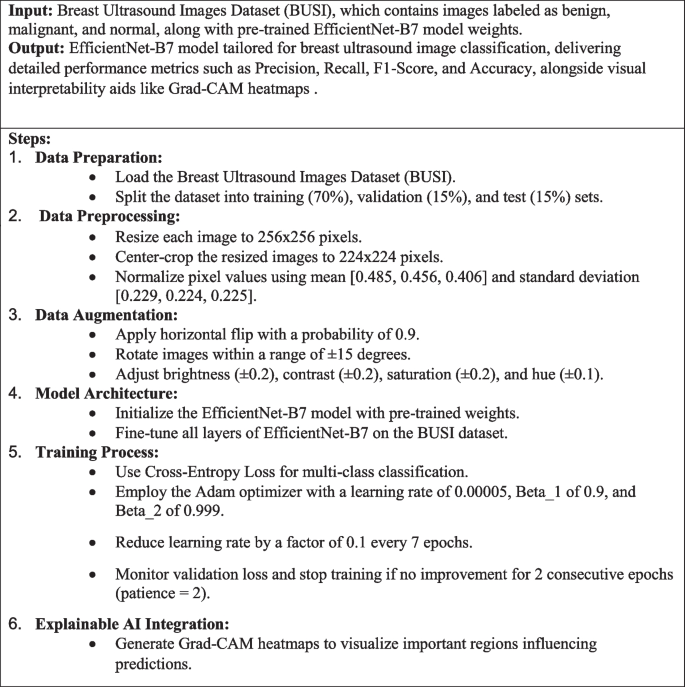
On this examine, Breast Ultrasound Photos Dataset (Dataset_BUSI_with_GT), which incorporates a complete of 780 pictures divided into three classes: benign, malignant, and regular. Every picture is paired with a corresponding masks picture that delineates the areas of curiosity, important for correct lesion localization and classification. The dataset was meticulously partitioned into coaching (70%), validation (15%), and check (15%) units, guaranteeing a balanced illustration of every class throughout all subsets. Throughout preprocessing, pictures have been rigorously resized to 256 × 256 pixels after which center-cropped to 224 × 224 pixels to standardize the enter measurement for the EfficientNet-B7 mannequin. Moreover, the dataset underwent a radical augmentation course of, significantly enhancing the minority courses (malignant and regular) with transformations comparable to random horizontal flips, rotations, and colour jittering, to enhance mannequin robustness in opposition to variations in picture presentation. This complete dataset preparation ensures that the mannequin is educated on a various and consultant set of pictures, selling higher generalization and efficiency in scientific purposes. Desk 2 reveals the variety of pictures and augmentation strategies utilized to every class within the dataset. Determine 3 reveals Pattern pictures from the Breast Ultrasound Photos Dataset (BUSI) displaying benign, malignant, and regular classes together with their corresponding masks.

Masked pictures from the dataset
Information preprocessing
In getting ready the breast ultrasound pictures for evaluation, every picture was resized to 256 × 256 pixels after which cropped to 224 × 224 pixels to concentrate on the central space the place lesions are normally discovered. To enhance picture high quality and scale back noise, we utilized Gaussian filtering, which gently smooths the photographs, and Sobel filtering to focus on edges. We additionally enhanced distinction by way of histogram equalization, making necessary options extra seen. To handle class imbalances, we augmented the photographs by randomly flipping, rotating, and adjusting colours, significantly for much less widespread classes like malignant and regular instances. Moreover, the pixel values have been normalized to match the pre-trained EfficientNet-B7 mannequin’s necessities, guaranteeing constant and high-quality enter information for correct classification. These preprocessing steps have been designed to boost mannequin robustness and enhance classification accuracy. (Eq. 1) blurs the picture I by convolving it with a Gaussian kernel (:G)σ, the place σ controls the unfold of the blur. (Eq. 2) Computes the gradient E of the picture I, which highlights the sides and transitions inside the picture. (Eq. 3) Applies histogram equalization to the picture I to boost distinction by redistributing pixel intensities. Determine 4 reveals the Examples of breast ultrasound pictures displaying (a) Precise Picture, (b) Masks, and (c) Overlayed Picture for various classes, benign, malignant, and regular.

Masks and overlayed precise pictures
$$:{I}_{textual content{blurred}}=Itext{*}Gleft({upsigma:}proper)$$
(1)
$$:E:=:nabla:I$$
(2)
$$:{I}_{textual content{equalized}}=textual content{HistEqual}left(Iright)$$
(3)
On this examine, every ultrasound picture was first resized to 256 × 256 pixels to make sure a constant enter measurement throughout the dataset, adopted by center-cropping to 224 × 224 pixels to concentrate on the central space, which generally incorporates the lesions of curiosity. This course of, as proven in (Eq. 4), standardizes the enter for the EfficientNet-B7 mannequin whereas preserving crucial options, as depicted in (Eq. 5). To handle the difficulty of sophistication imbalance, significantly for the much less widespread malignant and regular courses, we utilized numerous information augmentation strategies. These included a 90% likelihood of horizontal flipping (Eq. 6) and random rotations inside ± 15 levels (Eq. 7), simulating completely different orientations and enhancing the mannequin’s means to deal with diverse ultrasound scan situations. Moreover, we adjusted the brightness, distinction, saturation, and hue of the photographs (Eqs. 8–11) to simulate completely different lighting situations and colour variations, making the mannequin extra sturdy. The examine employed superior augmentation strategies, guaranteeing the mannequin may successfully classify high-resolution pictures and study key options. Furthermore, the mixing of Explainable AI strategies, comparable to Grad-CAM, supplied visible explanations for the mannequin’s choices, serving to clinicians perceive which areas of the picture influenced the classification. These strategies improve the mannequin’s accuracy and reliability, making it a helpful software for bettering diagnostic outcomes in scientific settings. Desk 3 outlines the parameters for the augmentation strategies, and Fig. 5 reveals their affect on a medical ultrasound picture.
$$I_{resized}=Resize(I, (256, 256))$$
(4)
$$I_{cropped}=CenterCrop(I_{resized}, (224, 224))$$
(5)
$$I_{flipped}=RandomHorizontalFlip(I_{norm}, p)$$
(6)
the place p=0.9.
$$I_{rotated}=RandomRotation(I_{norm}, uptheta)$$
(7)

Illustration of knowledge augmentation strategies on an ultrasound picture
$$:{I}_{textual content{brightness}}=textual content{ColorJitter}left({I}_{textual content{norm}},{upbeta:}proper)$$
(8)
the place β∈[0.8,1.2].
$$:{I}_{textual content{distinction}}=textual content{ColorJitter}left({I}_{textual content{norm}},cright)$$
(9)
the place c∈[0.8,1.2].
$$:{I}_{textual content{saturation}}=textual content{ColorJitter}left({I}_{textual content{norm}},sright)$$
(10)
the place s∈[0.8,1.2].
$$:{I}_{textual content{hue}}=textual content{ColorJitter}left({I}_{textual content{norm}},hright)$$
(11)
the place h∈[− 0.1,0.1].
The pixel values of the photographs have been normalized utilizing a imply of [0.485, 0.456, 0.406] and a typical deviation of [0.229, 0.224, 0.225]. This normalization step was crucial to standardize the enter information distribution, aligning with the pre-trained EfficientNet-B7 mannequin’s anticipated enter format. Normalizing the pixel values ensured that the mannequin coaching course of was steady and environment friendly, facilitating higher convergence and improved mannequin efficiency. (Eq. 12) reveals the Adjustment of the picture pixel values primarily based on the imply and customary deviation, guaranteeing the info distribution matches the mannequin’s coaching situations. (Eq. 13) Applies batch normalization to the picture I to stabilize and speed up coaching by normalizing the pixel values.
$$:{I}_{textual content{norm}}=frac{{I}_{textual content{cropped}}-{upmu:}}{{upsigma:}}$$
(12)
the place μ=[0.485,0.456,0.406] and σ=[0.229,0.224,0.225].
$$I_{bn}=frac{I-mathrmmu}{sqrt{mathrmsigma^2+}}gamma+$$
(13)
Proposed methodology
Within the proposed methodology, the EfficientNet-B7 mannequin is fine-tuned on the BUSI dataset to categorise breast ultrasound pictures into benign, malignant, and regular classes as proven in algorithm 1. The methodology employs superior information augmentation strategies, together with RandomHorizontalFlip, RandomRotation, and ColorJitter, particularly concentrating on minority courses to boost information variety and mannequin robustness. An early stopping mechanism is built-in to forestall overfitting, guaranteeing optimum mannequin efficiency and generalization to new information.
Algorithm 1 EfficientNet-B7 primarily based breast ultrasound picture classification
The core mannequin utilized on this examine is EfficientNet-B7, a cutting-edge convolutional neural community identified for its outstanding stability between accuracy and computational effectivity. EfficientNet-B7 is a part of the EfficientNet household, which scales community dimensions—depth, width, and determination—uniformly utilizing a compound scaling methodology, leading to a mannequin that achieves superior efficiency with fewer parameters in comparison with conventional architectures [18]. This mannequin is especially well-suited for medical picture evaluation because of its means to seize intricate patterns and options in high-resolution pictures, which is essential for precisely distinguishing between benign, malignant, and regular breast ultrasound pictures. The Fig. 6 depicts Weight slice Visualization 2 and Fig. 7 depicts Permuted Weight Visualization 2.

Weight slice visualization 2

Permuted weight visualization 2
$$:d={{upalpha:}}^{l},hspace{1em}w={{upbeta:}}^{l},hspace{1em}r={{upgamma:}}^{l}$$
(14)
the place d, w, and r are depth, width, and determination.
$$:O=left(Itext{*}Kright)+b$$
(15)
the place I is enter, Okay is kernel, b is bias.
$$:{I}_{textual content{hole}}=frac{1}{Htimes:W}{sum:}_{i=1}^{H}{sum:}_{j=1}^{W}{I}_{i,j}$$
(16)
$$:{O}_{textual content{fc}}=Wcdot:{I}_{textual content{hole}}+b$$
(17)
$$:{I}_{textual content{dropout}}=Icdot:textual content{Bernoulli}left(pright)$$
(18)
the place p is the dropout likelihood.
$$:F=textual content{Conv2D}left({I}_{textual content{enter}},Kright)$$
(19)
$$:{A}^{okay}=textual content{ReLU}left({F}^{okay}proper)$$
(20)
$$:P=textual content{MaxPooling}left(Aright)$$
(21)
$$:{a}_{i}={upsigma:}left({W}_{i}cdot:x+{b}_{i}proper)$$
(22)
On this examine, your entire EfficientNet-B7 structure was fine-tuned somewhat than freezing the preliminary layers and solely coaching the ultimate layers. This complete fine-tuning method permits the mannequin to adapt extra successfully to the distinctive traits of breast ultrasound pictures, which can differ considerably from the photographs the mannequin was initially pre-trained on (e.g., ImageNet). Superb-tuning all layers helps the mannequin to study extra domain-specific options, enhancing its means to precisely classify the photographs. This method permits the mannequin to regulate its discovered options throughout all layers, resulting in improved efficiency within the particular activity of breast ultrasound picture classification.
To forestall overfitting, an early stopping mechanism was carried out within the coaching course of. Early stopping screens the validation loss and halts coaching if there isn’t a enchancment after a specified variety of epochs, which is known as persistence. On this examine, a persistence of two epochs was set, that means the coaching would cease if the validation loss didn’t lower for 2 consecutive epochs. This method helps to keep away from overfitting by guaranteeing that the mannequin doesn’t proceed to study from noise within the coaching information, thereby sustaining generalization functionality. Early stopping not solely prevents overfitting but in addition optimizes computational assets by stopping coaching when additional enhancements are unlikely. (Eq. 23) Specifies the early stopping criterion primarily based on validation loss (:{L}_{textual content{val}}), halting coaching if no enchancment is noticed for p epochs.
$$:hspace{1em}{L}_{textual content{val}}>{L}_{{textual content{val}}_{textual content{min}}}hspace{1em}$$
(23)
The mannequin was educated utilizing a cross-entropy loss perform, which is well-suited for multi-class classification issues like this one. Cross-entropy loss measures the efficiency of a classification mannequin whose output is a likelihood worth between 0 and 1, quantifying the distinction between the expected chances and the precise class labels. The Adam optimizer, identified for its computational effectivity and low reminiscence necessities, was chosen to replace the mannequin weights. The training fee was set to 0.00005, balancing the necessity for important updates with the steadiness required for convergence. Moreover, a studying fee scheduler with a step measurement of seven and a gamma of 0.1 was employed [19]. This scheduler reduces the educational fee by an element of 0.1 each 7 epochs, permitting the mannequin to fine-tune its weights extra delicately as coaching progresses, which is especially helpful in avoiding overshooting the minima of the loss perform. (Eq. 24) Defines the cross-entropy loss perform, measuring the discrepancy between predicted chances and true labels for classification duties. (Eq. 25) Updates the transferring common of gradients (:{m}_{t}) within the Adam optimizer with decay fee (:{{upbeta:}}_{1}). (Eq. 26) Updates the transferring common of squared gradients (:{v}_{t}) within the Adam optimizer with decay fee (:{{upbeta:}}_{2}). (Eq. 27) Computes the bias-corrected first second estimate (:widehat{{m}_{t}}) in Adam optimization. (Eq. 28) Computes the bias-corrected second second estimate (:widehat{{v}_{t}}) in Adam optimization. (Eq. 29) Updates the mannequin parameters θ within the Adam optimizer utilizing the educational fee 𝛼. (Eq. 30) Adjusts the educational fee 𝛼 by multiplying the outdated studying fee with a specified issue. Desk 4 reveals the lists of the important thing parameters and settings used through the coaching of the EfficientNet-B7 mannequin.
$$:L=-{sum:}_{i=1}^{N}{y}_{i}textual content{log}left(widehat{{y}_{i}}proper)$$
(24)
$$:{m}_{t}={{upbeta:}}_{1}{m}_{t-1}+left(1-{{upbeta:}}_{1}proper){g}_{t}$$
(25)
$$:{v}_{t}={{upbeta:}}_{2}{v}_{t-1}+left(1-{{upbeta:}}_{2}proper){g}_{t}^{2}$$
(26)
$$:hat{m}_{t}=frac{{m}_{t}}{1-{{upbeta:}}_{1}^{t}}$$
(27)
$$:hat{v}_{t}=frac{{v}_{t}}{1-{{upbeta:}}_{2}^{t}}$$
(28)
$$theta_t=theta_{t-1}-alphafrac{overbrace{m_t}}{sqrt{overbrace{v_t+in}}}$$
(29)
$$:{{upalpha:}}_{textual content{new}}={{upalpha:}}_{textual content{outdated}}occasions:$$
(30)
Coaching and validation
The coaching course of for the EfficientNet-B7 mannequin includes fine-tuning on the BUSI dataset with a concentrate on classifying breast ultrasound pictures into benign, malignant, and regular classes. Information augmentation strategies comparable to RandomHorizontalFlip, RandomRotation, and ColorJitter are employed to handle class imbalance and improve the range of coaching information. The mannequin is educated utilizing a cross-entropy loss perform, with the Adam optimizer managing weight updates, and a studying fee scheduler adjusting the educational fee to refine coaching. Early stopping is carried out to watch validation loss, halting coaching if no enchancment is noticed over two consecutive epochs, thereby stopping overfitting. All through the coaching, efficiency metrics together with precision, recall, F1-score, and accuracy are evaluated, guaranteeing the mannequin’s robustness and effectiveness in precisely classifying ultrasound pictures.
Grad-CAM as explainable AI
Gradient-weighted Class Activation Mapping (Grad-CAM) is a robust explainable AI approach that gives visible explanations for deep studying mannequin predictions, significantly within the context of picture classification. Grad-CAM generates a heatmap that highlights the areas of an enter picture which are most influential within the mannequin’s decision-making course of. It really works by computing the gradients of the goal class rating with respect to the function maps of a particular convolutional layer. These gradients are then used to weight the function maps, emphasizing the areas which have probably the most important affect on the prediction. By overlaying this heatmap on the unique picture, Grad-CAM produces a visible illustration that makes it simpler to know which components of the picture the mannequin is specializing in. This transparency is essential in medical imaging purposes, comparable to breast ultrasound classification, because it permits clinicians to validate the mannequin’s choices and ensures that the mannequin is contemplating clinically related options. Grad-CAM thus enhances the interpretability of deep studying fashions, constructing belief and facilitating their integration into scientific workflows [20]. (Eq. 31) Computes the significance weights (:{{upalpha:}}_{okay}^{c}) of the function map (:{A}^{okay}) for the category 𝑐c utilizing gradients. (Eq. 32) Generates the Grad-CAM heatmap (:{L}_{textual content{Grad-CAM}}^{c}) by weighting function maps (:{A}^{okay}:)with their significance (:{{upalpha:}}_{okay}^{c}) and making use of ReLU. (Eq. 33) Defines Shapley worth (:{{upvarphi:}}_{i}:)for function (:i), measuring its contribution to the prediction by averaging its marginal contributions throughout all potential subsets 𝑆. (Eq. 34) Computes the gradient (:{g}_{t}) of the loss perform L with respect to parameters θ at time t. (Eq. 35) Updates the parameters θ utilizing gradient descent with studying fee η. Desk 5 reveals the parameters and settings used for producing Grad-CAM heatmaps, enhancing the interpretability of the mannequin’s predictions. Determine 8 reveals the Grad-CAM heatmap visualization highlighting necessary areas influencing classification choices.

Grad-CAM heatmap visualization
$$:{{upalpha:}}_{okay}^{c}=frac{1}{Z}{sum:}_{i}{sum:}_{j}frac{partial:{y}^{c}}{partial:{A}_{ij}^{okay}}$$
(31)
$$:{L}_{textual content{Grad-CAM}}^{c}=textual content{ReLU}left({sum:}_{okay}{{upalpha:}}_{okay}^{c}{A}^{okay}proper)$$
(32)
$$:{{upvarphi:}}_{i}={sum:}_{Ssubseteq:Nsetminus:left{iright}}fracSright!left[fleft(Scup:left{iright}right)-fleft(Sright)right]$$
(33)
$$:{g}_{t}={nabla:}_{{uptheta:}}Lleft({{uptheta:}}_{t-1}proper)$$
(34)
$$:{{uptheta:}}_{t}={{uptheta:}}_{t-1}-{upeta:}{g}_{t}$$
(35)
Statistical evaluation
This evaluation rigorously evaluates a breast ultrasound classification mannequin utilizing key metrics comparable to precision, recall, F1-score, and ROC-AUC, alongside error metrics like MAE, MSE, and RMSE, to make sure sturdy and correct efficiency. Precision measures the mannequin’s accuracy in predicting true optimistic instances, whereas recall assesses its means to seize all related situations. The F1-score balances precision and recall, offering a single effectiveness measure, and ROC curves with AUC values provide a complete view of the mannequin’s diagnostic capabilities throughout completely different courses (benign, malignant, regular). The confusion matrix visualizes the mannequin’s efficiency, figuring out areas for enchancment, and the inclusion of error metrics like MAE, MSE, and RMSE additional quantifies prediction accuracy and sensitivity to outliers. These mixed metrics provide a radical evaluation of the mannequin’s reliability and effectiveness in scientific purposes, significantly in minimizing false positives and guaranteeing early detection in medical analysis.